
理解 useEffect
原文: A Complete Guide to useEffect
开始聊 effect 之前, 我们先开始聊一聊组件的渲染.
以下是一个计时器组件. 关注其中高亮的部分:
1 | function Counter() { |
以上的代码实际上发生了什么呢? count 是不是在时刻关注我们的状态(state)变化, 然后根据这个变化自动更新呢? 这个猜测十分符合直觉, 如果你是 React 初学者, 这个想法可能会为你理解 React 带来比较大的帮助. 但是实际上, 这个理解并不准确. 我写过一篇关于这个话题的文章, 这才是准确的心智模型
在上面的例子中, count 仅仅是个数字而已. 内部并没有”数据绑定”, “观察者”, “代理”等等的逻辑. 就像下面的代码示例一样, 它仅仅只是一个数字:
1 | const count = 42 |
当组件第一次渲染的时候, 从 useState() 中读取到的 count 是 0. 当我们调用了 setCount(1) 之后, React 会重新调用我们的组件. 这一次 count 值将会是 1, 以此类推:
1 | // 首次渲染 |
无论何时, 状态更新之后, React 都会重新调用我们的组件. 每一次渲染的结果都会”看到”组件内部的 count 状态值, 而这个值在函数中实际上是一个常量.
所以说以下这一行代码并没有任何特殊的数据绑定逻辑:
1 | <p>You clicked {count} times</p> |
它仅仅只是将数字的值添加到渲染结果中而已. 这个数字由 React 提供. 当我们调用 setCount 的时候, React 会用一个最新的 count 值来重新调用我们的组件. 然后 React 更新 DOM, 以匹配最新的渲染结果.
这里的关键点是: count 值在每次渲染的过程中, 都是一个固定的常量. 只有组件被重新调用, 每一次渲染都”看到了”对应的 count 值, 同时每一次渲染的 count 都互不关联.
(想要更深入地了解具体的渲染流程, 可以查看这篇文章: React 作为 UI 运行时)
每次渲染都有自己的事件处理器
接下来开始看事件处理器.
查看下面的示例. 我们设置了一个 3 秒的定时器, 3 秒之后弹出 count 值:
1 | function Counter() { |
现在我按步骤做了以下几件事情:
- 将计时器的值增加到 3
- 点击“Show alert”
- 在定时器的回调(
alert函数)执行之前将计时器的值增加到 5
你认为 alert 的结果会是什么呢? 是 alert 时的 state 值 5, 还是点击时的 state 值 3?
剧透:
可以在这里自己试一试!
如果这个示例对你来说很费解, 可以想象一个更实际的例子: 假设现在有一个聊天应用, 我们将 count 类比为当前接受的消息对应的 ID, 存储在 state 中, 将按钮类比为发送消息的按钮, 这样可能会更容易理解.
这篇文章详细解释了出现上述结果的原因, 正确答案是 3.
alert 会”捕捉”点击当时 state 的值.
(当然, 我们可以修改代码以实现其他的行为, 但是目前我只关注默认场景. 当我们在建立一个全新心智模型的时候, 要尽可能选择最简单的方式, 这样能帮助我们更容易地建立全新的心智模型.)
那么其中的原理是什么呢?
我们先前提到过, count 值在每次被调用时都是一个常量. 有必要重点指出的是 – 我们的函数(组件)会被调用多次(每次渲染被调用一次), 每一次被调用时, 这个 count 都是由 useState 控制的一个特定值.
这个特性并非 React 独有 – 普通的函数也是这样工作的:
1 | function sayHi(person) { |
在这个示例中, 外部的 someone 变量被多次重新赋值. (就像在 React 中, 当前组件的 state 不断变化一样. ) 在 sayHi 内部, 有一个变量 name, 它会读取 person 的 name 属性. 这个变量在函数内部, 每次调用之间都是独立的. 因此, 当定时器的回调被调用的时候, 每次 alert 都会”记住”当时的 name.
这也解释了我们的事件处理器是如何在点击的当下”捕捉” count 值的. 同理, 每次渲染都能”看到”自己的 count:
1 | // 首次渲染 |
每一次渲染, 都会返回各自版本的 handleAlertClick, 并且有各自的 count:
1 | // 首次渲染 |
这也是为什么, 在这里的示例中, 事件处理器”属于”各自的渲染, 当用户点击的时候, 会使用那次渲染的 count 值.
对于每一次渲染, 内部的 props 和 state 始终保持不变, 并且每次渲染都是独立的. 既然每次渲染的 props 和 state 各自独立, 消费它们的部分(包括事件处理器), 在渲染间也各自独立, 都从属于特定的渲染. 因此事件处理器内部的异步函数也会”看到”同样的 count 值.
边注: 我在 handleAlertClick 中直接使用了 count 值. 这样的替换是安全的, 因为在一次渲染流程中, count 值不可能有变化. 它被声明为 const, 且是一个不可变的数字. 同样的原则在对象中仍然适用, 不过我们必须要确保避免改变(mutate)状态的值. 做法是用一个新创建的对象去调用 setSomething(newObj), 而不改变这个对象. 这样的话, 前一次渲染的状态(state)值就能够保持不被下一次渲染修改.
每次渲染都有自己的副作用
这篇文章的主要内容本该是关于副作用函数(effect)的, 现在我们会开始详细介绍它. 其实, 副作用和以上两部分的行为类似, 每次渲染都有自己的副作用函数.
我们回到 React 文档中的例子:
1 | function Counter() { |
现在有一个问题: effect 是如何读取到 count 的最新值的?
在 effect 函数的内部有一些数据绑定或者订阅的逻辑, 使得 effect 函数每次都能读取到 count 的最新值? 还是 count 是一个可变的值, React 在组件的内部维护了这个值, 因此我们的 effect 函数能够读取到最新值?
都不是的.
先前我们已经知道, count 在每次特定的组件渲染流程中, 都是一个常量. 事件处理器从它所属的渲染流程中读取到了对应的 count 值, 因为 count 是处于对应作用域的变量. 在 effect 函数中也不例外!
并不是在一个”不会变化”的副作用方法中, count 变量值时刻变化. 而是每一次渲染, 副作用函数本身都不一样.
同样地, 每个版本的副作用方法读取到的都是当次渲染内的 count 值:
1 | // 首次渲染 |
React 会记住每一次你所提供的副作用方法, 在当次渲染流程结束, UI 呈现出对应变化之后, 调用这个副作用方法.
尽管每一次渲染的副作用方法看起来没有差别(功能都是更新文档的标题), 但是实际上每一次渲染这个方法都是不一样的 – 并且每一个副作用方法都会看到”渲染”当次的 props 和 state.
为了便于理解, 你可以把副作用方法当做是每次渲染的结果.
但严格来说, 它们并不是渲染结果(React 不将副作用函数设计为渲染结果的原因是: 能够通过简单的语法实现 Hooks 的组合, 减少运行时的开销). 但是考虑到我们现在的目的是建立全新的心智模型, 可以在概念上认为副作用函数是某一次渲染的结果.
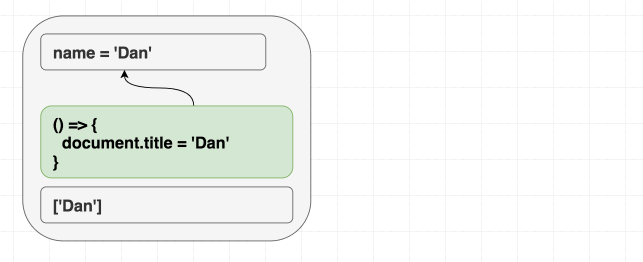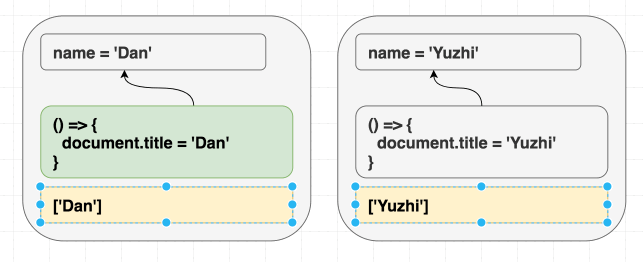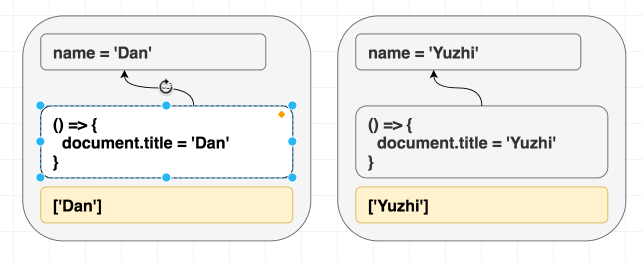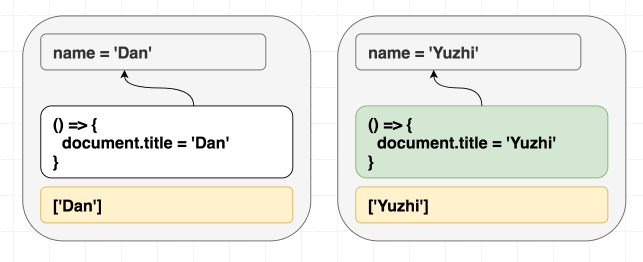
现在来巩固以上的内容, 首先回顾首次渲染:
- React: 当 state 值为
0的时候, 给我你希望渲染的 UI 内容. - 组件:
- 这是我要渲染的内容:
<p>You clicked 0 times</p>. - 渲染结束之后请执行这个副作用方法:
() => { document.title = 'You clicked 0 times' }.
- 这是我要渲染的内容:
- React: 好的, 更新 UI. Hey, 浏览器, 我想要在 DOM 中添加一些内容.
- 浏览器: 好的, 我把它们绘制到屏幕中.
- React: 好的, 我准备开始执行副作用方法了.
- 执行
() => { document.title = 'You clicked 0 times' }.
- 执行
然后回顾点击之后的渲染流程:
- 组件: Hey, React, 把我状态(state)中的
count值设置为1. - React: 当
count更新为1的时候, 把对应的 UI 返回给我吧. - 组件:
- 这是渲染的结果:
<p>You clicked 1 times</p>. - 记得执行这个副作用方法:
() => { document.title = 'You clicked 1 times' }.
- 这是渲染的结果:
- React: 好的, 更新 UI. Hey, 浏览器, 我已经修改好 DOM 了.
- 浏览器: 好的, 我把它们绘制到屏幕中.
- React: OK, 我现在开始执行副作用方法.
- 执行
() => { document.title = 'You clicked 1 times' }.
- 执行
每次渲染的所有值都属于当次渲染
我们知道了, 副作用方法在每次渲染之后都会执行, 从概念上可以将副作用方法理解为组件输出内容的一部分, 并且副作用方法能够”看到”当次渲染的 props 和 state.
现在我们来做一次实验. 查看下面的代码:
1 | function Counter() { |
如果我在每次延迟的时间段内点击多次, 最终输出的值会是怎样的呢?
_剧透_
你可能会认为这是个糊弄你的题目, 最终的结果会很出人意料. 其实并不是! 我们来看这一系列的输出 – 每一个输出都属于特定的渲染, 因此每一次输出都是自己的 count 值. 可以在这里自己尝试一下.
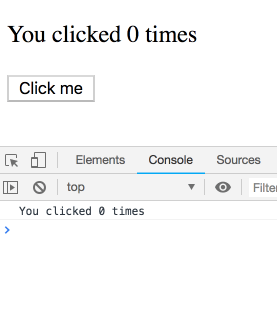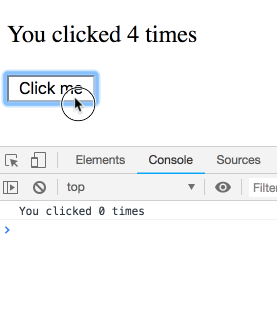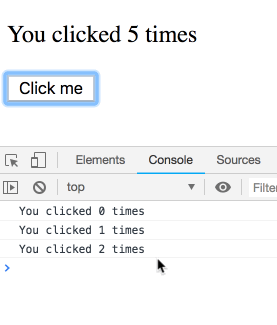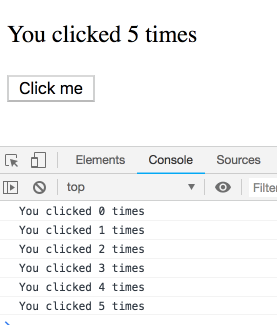
你可能会觉得: “当然是这样输出的, 否则是怎样的呢?”
不过, this.state 在类组件中的行为并不是这样. 很多人会把 useEffect 看作是和类组件概念中 componentDidUpdate 对应的方法:
1 | componentDidUpdate() { |
实际上并不是这样, this.state.count 始终是最新的 count 值, 但是 useEffect 中的则是当次渲染的值, 因此以上代码的结果, 输出的会是 5:
I think it’s ironic that Hooks rely so much on JavaScript closures, and yet it’s the class implementation that suffers from the canonical wrong-value-in-a-timeout confusion that’s often associated with closures. This is because the actual source of the confusion in this example is the mutation (React mutates this.state in classes to point to the latest state) and not closures themselves. (我觉得很有意思的是, Hooks 的实现十分依赖 JavaScript 中的闭包)
当我们需要锁定一个永远不会变化的值的时候, 使用闭包是最合适的手段. 这使得我们很容易能够推出正确答案, 因为你正在读取的值始终是一个常量. 既然我们现在已经知道了如何维持渲染时的 props 和 state, 可以开始尝试使用闭包对 class 版本的代码进行改造.
逆流而上
此刻我们已经得到了一个共识: 函数式组件在渲染时, 内部的每一项(包括事件处理器, 副作用方法, timeout 回调, API 调用等)都会”捕捉”渲染当时的 props 和 state.
因此以下两个例子其实是一致的:
1 | function Example(props) { |
1 | function Example(props) { |
从上面的代码可以看出, 不管我们是否在组件中提前读取了 state 或者 props 的值, 对副作用函数中读取到的结果都没有影响. 在单次渲染的作用域内, props 和 state 始终会保持不变. (将 props 解构能够使得这个行为更容易理解.)
在某些场景下, 我们可能会希望能够在副作用函数的回调中读取到最新的值而不是渲染当时的值. 最简单的方式是使用 ref, 在这篇文章的最后一部分我们有提到这一点.
有一点需要注意的是, 当我们希望在过去的渲染中读取到未来的 props 和 state 时, 实际上在逆流前进. 这当然没有错(在某些情况下甚至是必要的), 不过这样的行为看起来比较”不干净”, 违背了正常的模式. 不过其实 React 团队是刻意把函数式组件的行为设计成这样的, 这样一来, 用户就能够很明显地发现代码中的缺陷. 在类式组件中, 发现这类缺陷就比较困难.
这里有另一个版本计时器的例子, 模拟了在类式组件的对应行为:
1 | function Example() { |
在 React 中修改(mutate)某些值或许看起来很奇怪. 但是其实在类式组件中, React 就是这样为 this.state 赋值的. 与获取渲染当时的 props 和 state 不同的是, 类式组件读取 latestCount.current 的值, 它获取到的结果无法得到任何的保证, 在某一次回调中是这样的结果, 到了下一次或许又不一样了, 因为它的值是可变的. 这也是我们不愿意将这种行为设置成默认行为的原因.
清除副作用的函数
文档中提到, 某些副作用还需要存在对应的清除副作用的阶段. 本质上来说, 在这个阶段中我们做的事情, 就是撤销副作用(比如取消订阅事件.)
查看下面的代码:
1 | useEffect(() => { |
假如在首次渲染时, props 的值为 {id: 10}, 第二次渲染时, 值为 {id: 20}. 你或许会认为渲染流程是这样发生的:
- React 清除 props 为
{id: 10}时的副作用. - React 为
{id: 20}渲染对应的 UI. - React 为
{id: 20}执行对应的副作用方法.
(但是实际情况并不是这样的.)
如果你建立了以上的心智模型, 就会认为清除副作用的函数”看到了”旧的 props, 因为这个函数是在重新渲染之前执行的, 然后新的副作用函数”看到了”新的 props. 这个心智模型对于类式组件来说, 是完全正确的, 但是对于函数式组件, 情况并不是这样. 我们来看看原因是什么.
React 执行副作用方法的时机是浏览器绘制需要渲染的内容之后. 这样能够使得我们的应用体验更佳, 不阻塞浏览器的渲染. 清除副作用的方法同时也会延迟. 前一次渲染的副作用直到使用新的 props 开始重新渲染, 才会被清除:
- React 为
{id: 20}渲染对应的 UI. - 浏览器绘制内容, 我们看到
{id: 20}对应的 UI. - React 清除 props 为
{id: 10}时的副作用. - React 为
{id: 20}执行对应的副作用方法.
你或许会觉得奇怪, 为什么前一次渲染的副作用方法读取到的是前一次渲染的 props 值, 而不是此刻的 {id: 20}?
我们之前已经提过这个话题…… 🤔

先前章节的摘录:
组件渲染时内部的每一个函数(包括事件处理器, 副作用函数, timeout 回调, API 调用等), 都会”捕捉”当时的 props 和 state.
这样一来, 答案就很明显了. 清除副作用的函数没有读取最新的 props, 它始终会读取渲染当时定义的 props 和 state:
1 | // 首次渲染 props 是 {id: 10} |
首次渲染的清除函数, “看到”的 props 一定是 {id: 10}, 不可能是其他值.
这种形式使得 React 能够在执行绘制之后直接处理副作用函数, 提升应用性能. 旧的 props 始终存在, 当代码需要它的时候, 我们可以直接使用它们.
同步 而不是生命周期
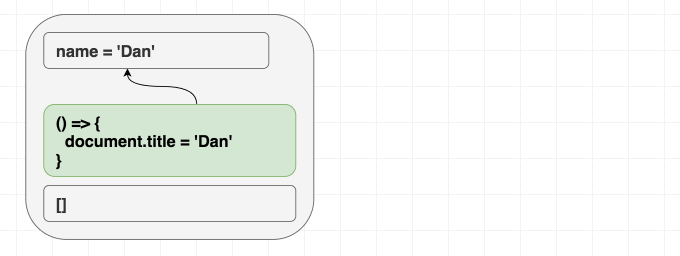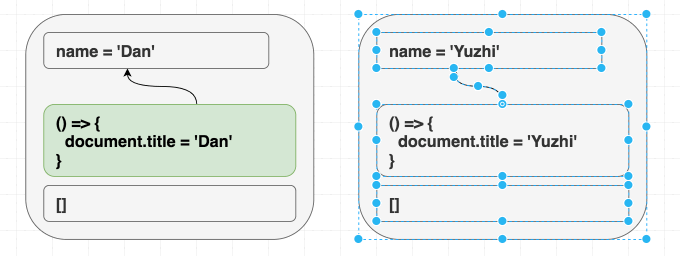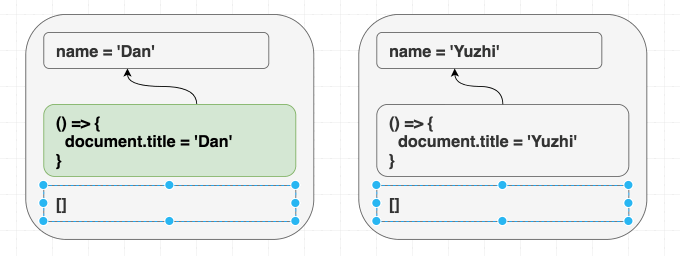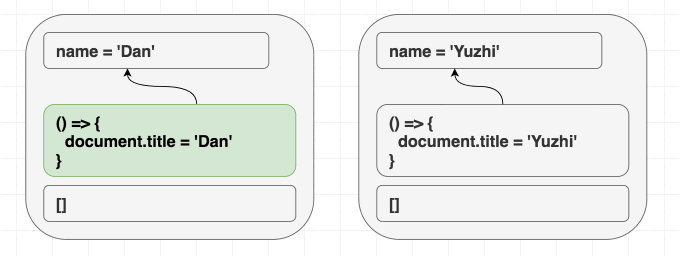
我喜欢 React 的原因之一是, 它统一描述了首次渲染的结果和后续的更新. 这种模式能够减少程序的熵.
举个例子, 如果我的组件是下面这样的:
1 | function Greeting({ name }) { |
不管是先渲染 <Greeting name="Dan" />, 然后渲染 <Greeting name="Yuzhi" />, 还是直接渲染 <Greeting name="Yuzhi" />. 最后的结果都是看到屏幕中呈现: “Hello, Yuzhi”.
人们常说: 重要的是旅程而不是目的地. 但是在 React 中, 情况就不是这样. React 只关注结果, 而非过程. 举个例子, 在 jQuery 中, 我们关注过程, 比如说使用 $.addClass 和 $.removeClass 来操控标签的 className, 就是针对过程的操作, 而在 React 中, 我们会直接声明 className 应该是什么样子的(关注结果).
React 会根据当前的 props 和 state 同步 DOM 的内容. 在渲染时, 挂载和更新做的 DOM 同步操作其实没有什么区别.
我们可以用同样的角度思考副作用函数. useEffect 函数使得我们能够根据 props 和 state 同步 React 树之外的内容.
1 | function Greeting({ name }) { |
这样的心智模型和我们所熟悉的 挂载/更新/卸载 有一点区别. 了解这个模型很重要. 如果你实现的副作用函数, 会根据是第一次渲染, 还是后续的渲染有不同的行为, 那么就和我们的设计理念背道而驰了! 如果我们的结果依赖的是”过程”而非”目的地”, 就是一次失败的同步.
不管我们是按照属性(A, B, C)的顺序进行渲染, 还是直接用属性 C 进行渲染, 其实基本上没有什么差别. 即使存在差别, 也只是暂时性的(比如我们在请求数据的时候, 会有一些细微的差别), 但是最终的结果始终是一致的.
有一个毋庸置疑的点是: 每一次渲染都执行所有的副作用其实很影响效率. (在某些情况下, 甚至会导致无限循环.)
那么我们怎么修复这个问题呢?
告诉 React 如何区别副作用函数的变化
我们已经知道了 React 如何 diff DOM, React 并没有在每次渲染的时候更新所有的 DOM, 而是更新有修改的部分.
当你更新以下组件
1 | <h1 className="Greeting">Hello, Dan</h1> |
为:
1 | <h1 className="Greeting">Hello, Yuzhi</h1> |
的时候, React 看到的是这样两个对象:
1 | const oldProps = { className: "Greeting", children: "Hello, Dan" } |
对于以上示例, React 会检查每一个 props, 然后判断出 children 有变化, 会去更新 DOM, className 没有变化, 因此不需要更新. 所以 React 只需要这样处理即可:
1 | domNode.innerText = "Hello, Yuzhi" |
那么针对副作用函数, 是否也能够只在必要的时候更新呢?
举个例子, 在以下函数中, 组件会因为 state 的更新而重新渲染:
1 | function Greeting({ name }) { |
但是我们的副作用函数并没有用到 counter 的值. 副作用函数只会根据 name 的属性值更新 document.title, 但是 name 属性值始终是一致的. 因此在每次 counter 值变化的时候给 document.title 重新赋值是完全没有必要的.
那么 React 如何分辨副作用函数是否需要变化呢?
1 | let oldEffect = () => { |
并不能, React 在调用函数之前, 是无法分析出这个函数所做的事情的. 源代码和上述例子的区别就是: 源代码并不包含具体值, 而只是一个 name 属性.
因此, 我们要避免在不必要的情况下执行副作用函数, 方式是传入一个依赖数组参数到 useEffect 方法中, 只有当依赖数组中的值变化的时候, 副作用函数才会重新执行.
1 | useEffect(() => { |
以上的场景就好像是我们在告诉 React: “Hey React, 我知道你不能看到函数内部的内容, 但是我可以确保函数内部使用到的渲染相关的参数只有 name. “
如果前一次副作用函数执行时 name 的值与这一次执行时一致的话, 那么就可以跳过此次副作用函数的执行:
1 | const oldEffect = () => { |
如果依赖数组中的某个值在渲染前后有所差异, 那么这个副作用函数就必须执行. 同步所有值.
要确保依赖数组中参数的准确性 不要欺骗 React
欺骗 React 关于依赖数组中的内容会带来比较不好的后果. Intuitively, this makes sense, but I’ve seen pretty much everyone who tries useEffect with a mental model from classes try to cheat the rules. (And I did that too at first!)
1 | function SearchResults() { |
(关于 Hooks 的常见问题中, 已经详细说明了更合适的做法. 我们回到现在的例子:)
你或许会这样说: “但是我只希望在组件挂载的时候执行这个方法!”. 我们要记住这样一个原则: 如果你声明了依赖参数, 所有组件内部的值, 只要被副作用函数使用, 就一定要添加到依赖参数数组中. 包括 props, state, 函数等任何在组件内部使用的值.
但是有时候我们可能会遇到一些问题. 比如循环请求的情况, 或者是某个 socket 不断被重新创建的情况. 针对这些问题的处理方式并不是删除这个依赖. 后面我们会谈到如何解决这些问题.
在我们查看解决方案之前, 先深入了解一下我们的问题.
当你对 React 撒谎 传入了错误的依赖参数会发生什么
如果依赖数组中包含了所有副作用函数会用到的值, React 就能够知道何时需要重新执行副作用函数:
1 | useEffect(() => { |
(依赖数组中的值在渲染前后有所差异, 因此我们需要重新执行副作用函数.)
如果我们在依赖数组中传入空数组[], 新的副作用函数就不会被重新执行:
1 | useEffect(() => { |
(依赖数组前后一致, 因此跳过这次副作用函数的执行)
通过以上的场景对比, 问题就很明显地体现出来了. But the intuition can fool you in other cases where a class solution “jumps out” from your memory.
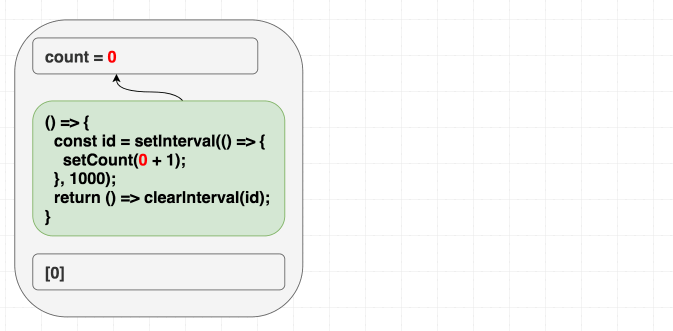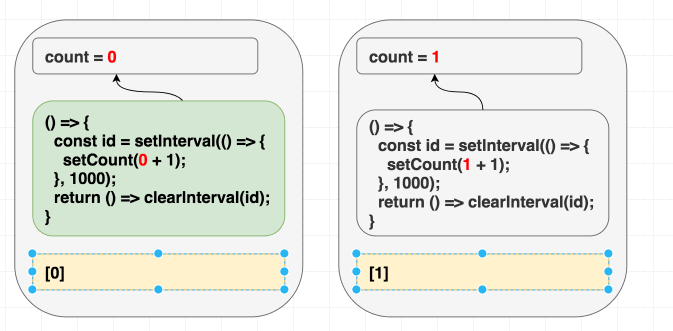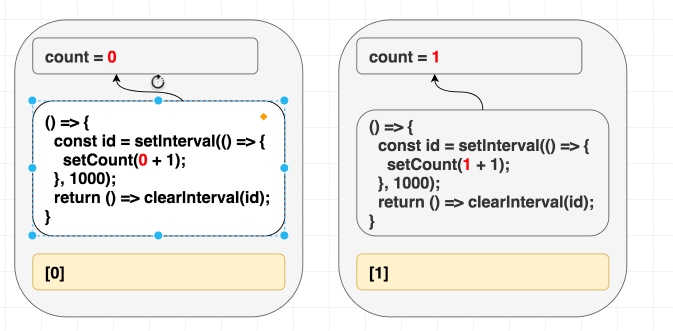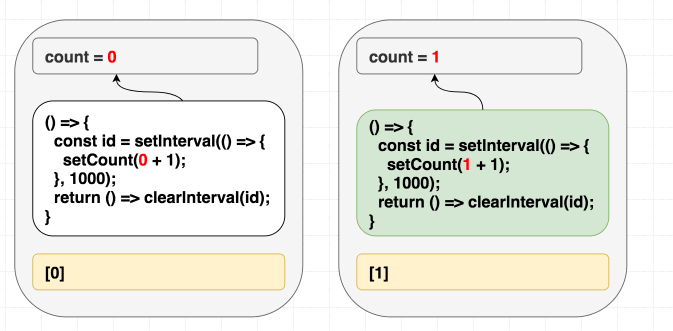
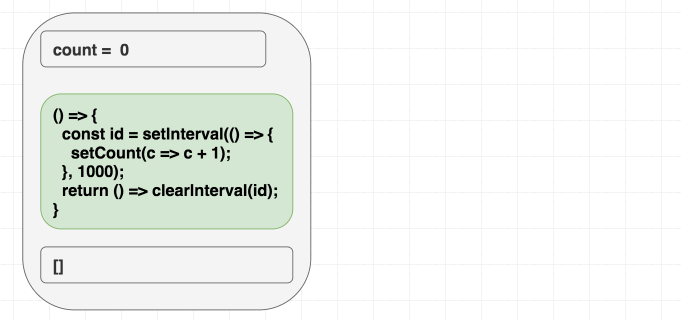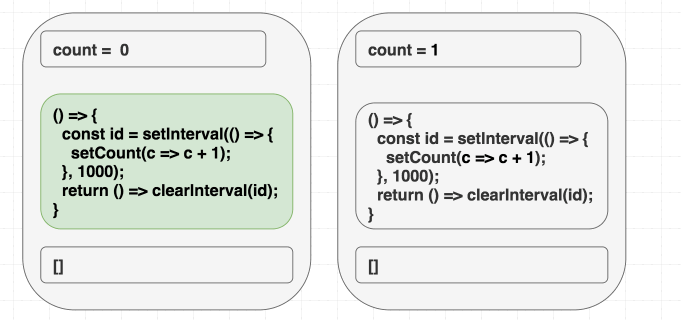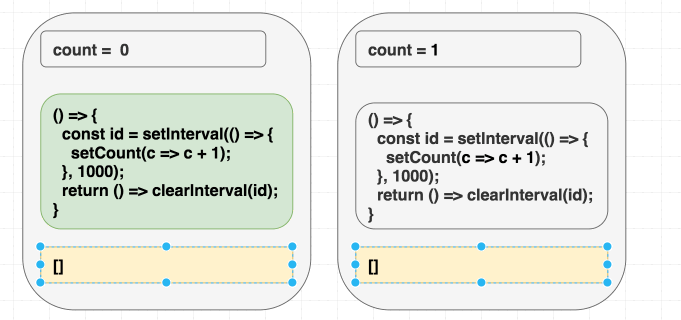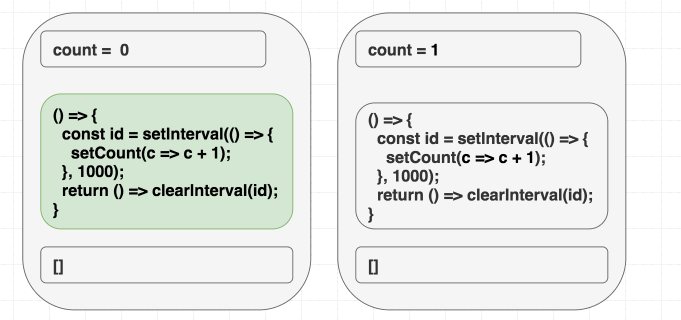
举个例子, 比如我们想要实现一个计数器, 每隔一秒数字加 1. 如果是类式组件的话, 我们会这样实现它: 在组件挂载的时候设置计时器函数, 组件卸载的时候清除.
这是具体的代码示例. 当我们想要把类式组件转换成函数式组件的时候, 会习惯性地使用 useEffect, 设置依赖参数为 [], 表示希望副作用函数只执行一次.
1 | function Counter() { |
但是真正执行了会发现, 结果并不是我们所预期的那样. 示例代码.
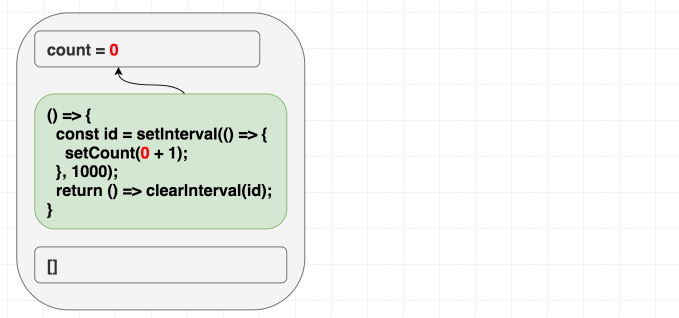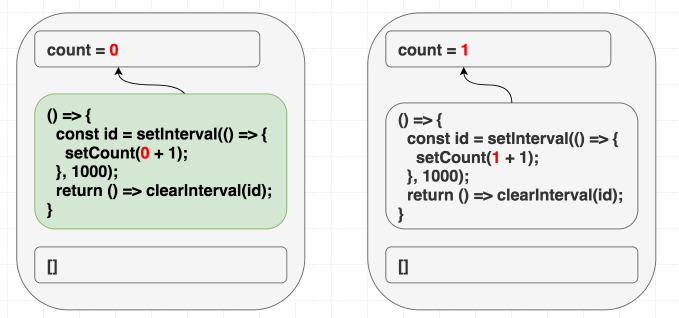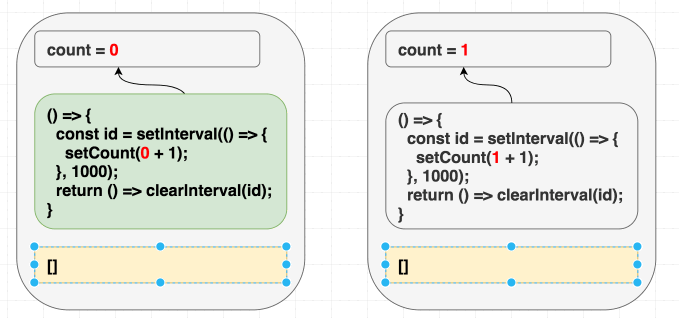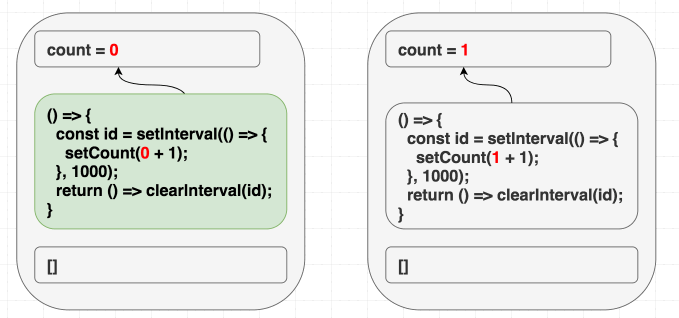
如果你的心智模型是这样的: “依赖的作用是让我声明什么时候需要重新触发副作用函数的执行”, 那么你写出来的代码就会很危险, 就像上面的例子一样. 但是问题是, 你希望只触发一次副作用方法, 因为这是一个间隔执行的 API, 实际上并没有错, 但是为什么会带来问题呢?
之前已经提到过, 副作用函数中使用到的所有值, 我们都要在依赖参数数组中声明. 由于内部使用到了 count, 但是我们并没有在依赖参数数组中声明, 引起 bug 只是时间的问题.
在首次渲染的时候, count 的值是 0. setCount(count + 1) 在首次渲染时实际执行的是 setCount(0 + 1). 但是因为我们声明的依赖数组参数中数组值为 [], 因此副作用函数不会变化, 每隔一秒执行的函数都是 setCount(0 + 1):
1 | // 首次渲染, state 是 0 |
由于在依赖参数中传递了一个空数组, 表明了我们的副作用函数不依赖任何值. 但是实际上副作用函数中存在依赖其他值的部分.
我们的副作用函数使用到了 count, 这个值声明于组件之内, 副作用函数之外:
1 | // highlight-next-line |
因此, 将依赖参数设置为 [] 会引起 bug. React 会对比依赖项数组中的内容, 然后跳过副作用函数的更新:
(依赖项中的内容始终没有区别, 因此跳过副作用函数的更新)
这样的问题比较难定位. 因此, 我建议大家在传递依赖项参数的时候对 React 保持诚实, 声明所有依赖参数. (我们提供了一个 lint 规则插件 以供用户在开发阶段使用.)
两种对依赖项保持诚实的方式
对依赖项保持诚实的方式有两种, 我们优先使用第一种方式, 在必要情况下使用第二种方式.
第一种方式是在依赖项数组中声明副作用函数的所有依赖, 针对以上的代码, 我们加上 count 作为依赖项:
1 | useEffect(() => { |
这样一来, 依赖项数组的声明就是正确的. 这并不是 _理想_ 的解决方案, 但是至少解决了问题. 现在只要 count 发生变化, 副作用函数就会重新执行, 副作用函数中读取 count 值的部分(setCount(count + 1))也会对应地发生变化:
1 | // 首次渲染, state 值为 0 |
这样修改之后, 问题解决了, 但是只要 count 一发生变化, 我们的间隔函数会不断被销毁重建. 这并不是我们所预期的行为:
(依赖项变化了, 因此我们重新执行副作用函数.)
第二种方式是改变副作用函数本身, 使得它不依赖外部经常会变化的值. 我们不想要欺骗 React 关于依赖项的内容, 于是尽可能得减少依赖项的内容.
现在我们开始看看减少依赖项的常用方法.
用函数的方式更新状态
现在我们的诉求是将 count 依赖从副作用方法的依赖中移除.
1 | useEffect(() => { |
为了达到我们的目的, 首先思考一个问题, count 的作用是什么呢? 看起来只有在 setCount 函数中才会用到它. 这样分析下来发现, 我们的副作用函数内其实可以不依赖 count. 当我们需要基于前一个状态更新当前状态的时候, 可以用 setState 的函数更新的方式更新状态.
1 | useEffect(() => { |
我倾向于将这些情况看作是”错误的依赖”. 如果我们的副作用函数的内容是 setCount(count + 1), 那么 count 就是一个必要的依赖项. 再仔细观察可以发现, 我们其实只依赖 count 的值用来计算 count + 1, 然后将计算得出的值抛给 React. 不过, React 其实早已知道当前的 count 值. 那么我们只需要告诉 React , 如何更新(+1) count 值, 就可以了, 不管当前的 count 值是多少, React 都能够正确计算最终的结果.
其实, setCount(c => c + 1) 做的就是这件事情. 你可以认为它传递了一个指令给 React, 告诉 React 应该如何更新状态的值. 这种更新状态的形式在一些其他场景下同样能够发挥很大的用处, 比如当我们需要合并状态的更新的时候.
注意, 此时我们将依赖从依赖数组中删除, 是真正不需要这个依赖了, 并没有欺骗 React, 我们的副作用函数确实不再需要读取 count 的值了.
(依赖项前后一致, 因此我们跳过副作用方法的执行)
可以在这里试一试.
尽管副作用函数只执行了一次, 属于第一次渲染 interval 回调函数依然在每次执行的时候, 完美地将 c => c + 1 的更新指令传达给了 React . 副作用函数不再依赖当前的 count 值, 因为 React 已经知道它的值了.
函数式更新与 Google Docs
还记得我们提到的, 副作用的心智模型与同步有关吗? 关于同步很有意思的一点是, 我们通常希望解耦系统和系统内部状态之间的通信. 举个例子, 当我们在 Google Docs 上编辑一份文档时, 并没有将整个页面内容传给服务器, 因为这样将会十分低效. 取而代之传递的是用户要做的动作.
当然我们的场景和 Google Docs 并不完全相同, 不过这种哲学在 effect 中同样适用. 只传递尽可能少的必需的信息到组件中. 更新状态的函数形式 setCount(c => c + 1) 比起 setCount(count + 1) 表达了更少的信息. 因为 setCount 依赖于当前 count 的值. 要把 React 写好, 我们应该秉承这样一个理念: 选择尽可能简单的 state 形式来表达 UI. 这种理念在状态的更新中同样适用.
对 _意图_ (而不是结果)进行编码, 与 Google Docs 解决协同编辑的方案很相似. 在 React 中用函数形式更新状态也是类似的实践. 这样的方式确保了, 即使更新来自于多个来源(事件处理器, 副作用函数订阅等), 也能够在一次批量操作中正确地执行, 并且能够预测更新的结果.
不过, setCount(c => c + 1) 的更新方式并不是特别完美. 因为这种形式看起来有点奇怪, 并且在某种程度上限制了我们的能力. 比如说, 当我们有两个状态变量, 且两者互相依赖, 或者是我们需要通过属性计算下一次渲染的状态值时, 就没办法使用函数式的更新方式. 不过幸运的是, 我们还有 useReducer, 它的更新方式与函数式的更新方式类似, 但是功能更加强大.
将状态更新从 actions 中解耦
现在修改以上的示例, 改为存在两个状态相关的变量: count 和 step. 我们的间隔执行函数不是每秒加 1, 而是每秒加上 step 变量所指的值:
1 | function Counter() { |
(这里是代码示例)
此刻我们并没有欺骗 React. 因为在副作用函数中使用了 step , 我们在依赖参数中也加上了它, 因此函数执行的结果始终是准确的.
对于上述的例子, 可以这样描述它的行为, 一旦 step 的值发生变化, 就重新开始执行这个间隔 (interval) 函数(因为 step 存在于依赖参数数组中). 大多数情况下, 这就是我们期待的结果: 销毁副作用函数并创建一个全新的副作用函数. 这是一个比较合理的模式, 正常情况下, 它也是唯一可以选择的更新方式.
不过, 如果我们期待的结果是这样的, 可能就没办法采取以上模式了: 我们不希望 step 变化引起副作用函数的销毁和重新创建, 那么应该怎么样才能把 step 从副作用函数的依赖数组中删除呢?
当我们遇到这样的场景: state 中的某个值依赖 state 中的另一个值, 可以考虑使用 useReducer 来达到更新状态的目的.
当你发现你写的设置状态相关的代码变成如下这样的时候: setSomething(something => ...), 就可以开始考虑使用 reducer 了. reducer 能够帮助我们将组件内部表达 actions 的逻辑和状态更新的逻辑进行解耦.
现在用 dispatch 依赖来替换代码中的 step 依赖:
1 | // highlight-next-line |
(这里是代码示例)
你或许会疑惑: “这样的方式为什么更好呢?” 因为 React 会确保 dispatch 函数在组件被创建之后, 在组件的生命周期间, 始终是一个常量. 因此在以上的示例中, 不需要再重新订阅 interval 函数.
至此, 已经解决了我们的问题!
(你或许会在依赖数组中省去 dispatch, setState, 或者 useRef 这些函数, 因为它们始终不会变化, 确实是这样, 是否将它们写入依赖数组中都无所谓.)
dispatch 函数做的事情, 并不是读取副作用函数内部的 state, 而是分发一个 action, 描述发生了什么. 这样的方式使得副作用函数能够和 step 状态解耦. 我们的副作用函数其实并不在意我们如何更新状态. 它只是单纯地告诉我们发生了什么. reducer 函数, 则只关注状态更新的逻辑:
1 | const initialState = { |
这里是代码示例.
为什么 useReducer 是 Hooks 的欺骗模式
我们已经知道, 当副作用函数中状态的更新依赖前一次渲染时的状态值, 或者另一个状态值的时候, 应该通过什么方式移除函数的依赖项. 那么当我们依赖属性 props 的时候, 应该怎么处理呢? 举个例子, 当我们的 API 是 <Counter step={1}>. 此时, 我们是否必须要在依赖数组中声明 props.step 呢?
有不必声明的方法! 可以将 reducer 函数本身置于我们的组件内部, 这样 reducer 就能够直接读取对应的 props:
1 | // highlight-next-line |
但是这种模式有个问题, 采取这种模式之后, 我们就无法进行一些必要的优化. 比较好的一点是, 在必要情况下, reducer 函数中能够任意读取所需的 props. (这里是代码示例.)
即使是在这样的情况下, 我们的 dispatch 函数依然能够保证在组件多次渲染的过程中始终保持不变. 因此在依赖项数组中忽略这个函数是完全合理的, 它不会引起副作用函数的重新执行.
你或许会对这种模式的底层原理感到好奇. 当我们在一个副作用函数中使用 reducer 的时候, 它是怎么”知道”另一次渲染时的 props 的呢? 这是因为当你调用 dispatch 的时候, React 会记住这个 action, 然后在下一次渲染的时候 _调用_ reducer. 此时, 最新的 props 就处于渲染的作用域中了, and you won’t be inside an effect.
这也是我倾向于将 useReducer 看作 Hooks 的”欺骗模式”的原因. 使用 useReducer, 我们能够将状态更新的逻辑和描述发生了什么的逻辑进行解耦. 同时帮助我们在依赖项数组中删除不必要的依赖, 避免不必要的副作用重新执行, 优化应用的性能.
将函数移动到副作用内部
还有一个比较常见的误区是认为函数不应该是副作用函数的依赖, 实际上并不是这样. 举个例子:
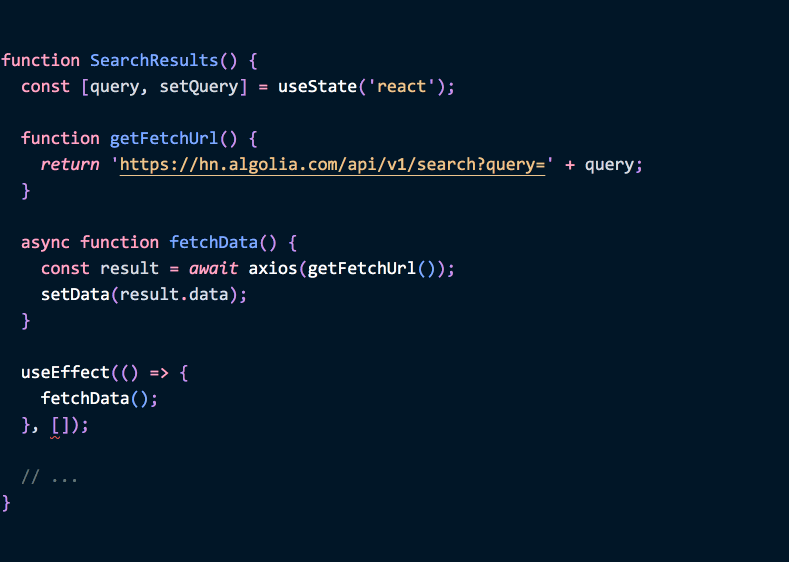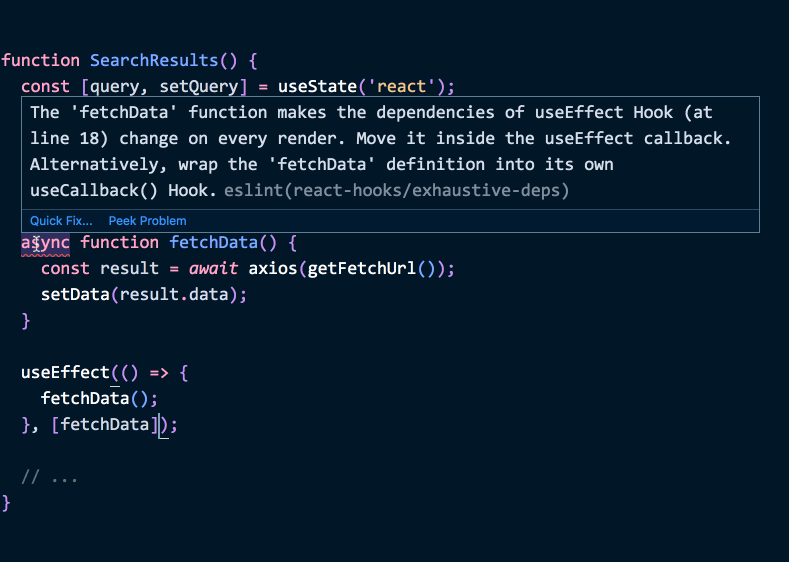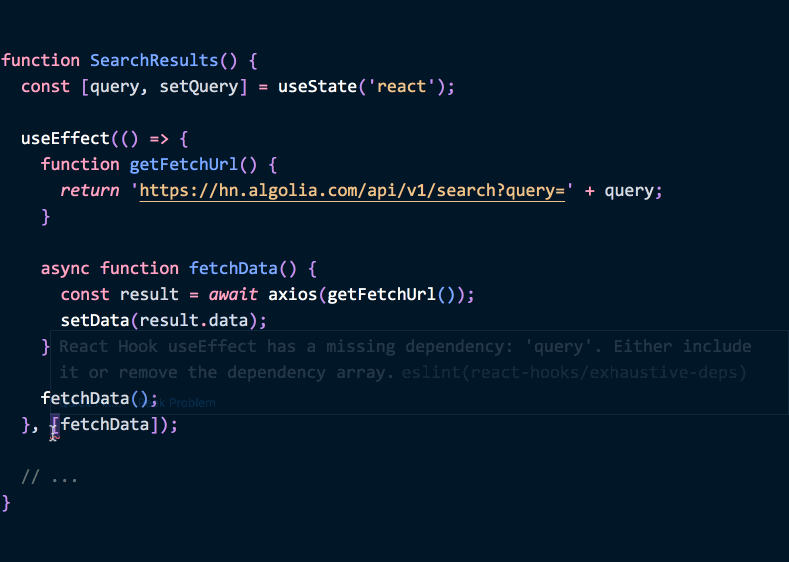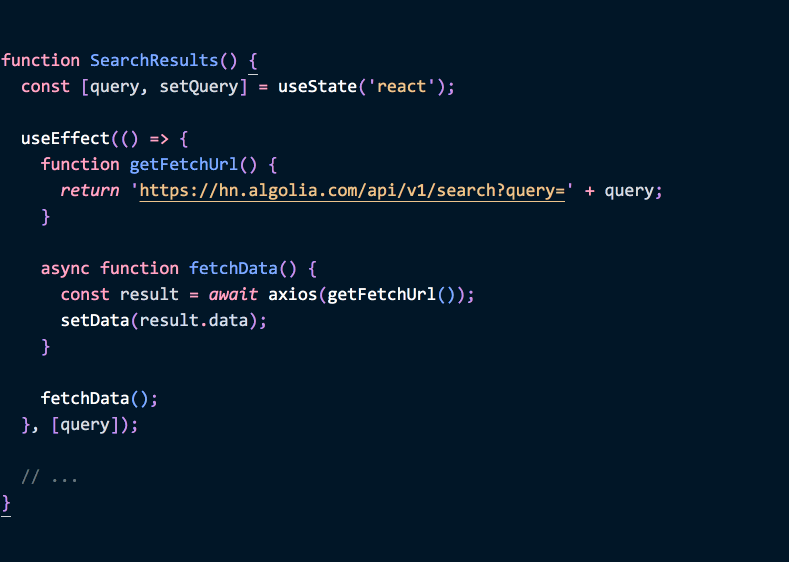
1 | function SearchResults() { |
代码实际上是有作用的. 但问题是, 简单地省略内部函数依赖, 当组件的规模变大之后, 我们会很难发现代码是否覆盖了所有情况.
假设我们的代码变成如下这样, 每一个函数变为原来的五倍规模:
1 | function SearchResults() { |
然后我们在这些函数中使用一些 state 或 props:
1 | function SearchResults() { |
如果我们忘了更新数组的依赖项, 遗漏了某些方法的话, 副作用函数就很可能无法准确同步 props 和 state 中的某些值. 引起一些 bug.
不过幸运的是, 有个简单的解决办法. 如果我们只在副作用函数内用到相关的函数, 可以直接将函数移到副作用函数内部:
1 | function SearchResults() { |
(这里是代码示例)
这样的方式有什么好处呢? 我们不再需要考虑 “transitive dependencies” . 依赖参数数组也不会再欺骗 React: 因为我们没有使用任何副作用函数外部的值.
如果后续更新 getFetchUrl 方法: 内部使用 state 中的 query 值, 就会注意到我们正在编辑副作用函数内部的内容依赖一个外部的值 – 因此我们需要在依赖参数中添加 query:
1 | function SearchResults() { |
(代码示例)
添加这项依赖的行为, 并不是单纯安抚 React 而已, 这样修改之后, 当 query 变化的情况下, 应用就会重新请求数据. useEffect 的设计强制要求开发者关注应用中数据流的变化情况, 并据此选择我们的副作用函数应该如何根据变化做出对应的同步, 而不是忽略数据流的变化, 等到用户发现 bug 之后才开始关注相关的逻辑.
开发者在开发过程中可以使用 eslint-plugin-react-hooks 插件, 并开启对应的代码规范提示规则: exhaustive-deps, 这个插件会分析代码中的副作用函数, 如果副作用函数的实现存在缺陷, 插件就会抛出对应的提示. 也就是说, 这个工具会在我们的组件没有正确处理数据流的情况下给我们提示.
无法将函数移入副作用内部的情况
在某些情况下, 我们可能不希望将函数移动到副作用函数内部. 比如说, 在多个副作用函数中都用到了同一个方法, 此时我们不希望拷贝粘贴一些重复的逻辑. 又或者, 这个函数是通过 props 传下来的.
这时我们要在依赖参数数组中忽略这个函数吗? 当然不. 再重申一次, 副作用函数对于依赖项的声明, 一定要保持诚实. 我们总是能够找到更好的解决方案的. 一个普遍存在的误解是: “函数始终不会变化”. 但是这篇文章阅读下来之后我们会发现, 事实并不是这样. 真实情况是, 定义在组件内部的函数在每一次渲染过程中都会有变化.
这种现象也揭示了一个问题. 如果我们现在有两个副作用函数, 调用了 getFetchUrl:
1 | function SearchResults() { |
在上面的示例中, 我们不会将 getFetchUrl 方法移动到副作用函数的内部, 因为如果这样的话, 副作用函数就无法共享 getFetchUrl 方法.
另一方面, 因为我们要对依赖项数组始终保持诚实, 就会遇到另一个问题. 由于我们的两个副作用函数都依赖 getFetchUrl (每一次渲染都有所差异), 如果传递了 getFetchUrl, 依赖项数组就基本上没什么用了: 因为每次渲染, 副作用函数都会重新执行:
1 | function SearchResults() { |
为了解决这个问题, 可以考虑在依赖项数组中直接省略 getFetchUrl. 但这并不是一个好的解决方案, 当我们要修改组件中的数据流的时候, 如果副作用函数消费了相关数据, 就会引起一些奇奇怪怪的问题. 比如我们先前碰到的, 间隔(interval)函数不更新的 bug.
其实还有其他更简单的解决方案.
第一个方案是, 如果一个函数没有消费组件作用域内的值, 可以将函数移到组件外部, 由于移到外部的函数不会因为渲染产生变化, 我们就不必在副作用函数中声明这个函数:
1 | // highlight-start |
getFetchUrl 并不存在于渲染阶段的作用域中, 也不会被组件数据流的变化影响, 我们就没有必要在依赖参数中声明它: 这个函数不可能因为 props 或者 state 的变化而产生变化.
还有一个方法就是, 将函数用 useCallback Hook 包裹起来:
1 | function SearchResults() { |
useCallback 所做的事情, 就像是给依赖参数检查加了另一层屏障. 从另一个角度入手解决了我们目前需要解决的问题 – 不修改依赖参数的声明, 而是针对所依赖的值本身做文章, 确保它只在必要的时候发生变化.
为什么这样的方式是有用的呢. 之前的两个例子中展示了针对 'react' 和 'redux' 的两个搜索结果. 如果我们现在希望加入一个输入框, 以供用户输入任意的 query 参数执行搜索. 这样一来, getFetchUrl 就需要从组件内部的作用域 state 中读取一些值.
此时依赖参数的数组中, 就应该加上 query:
1 | function SearchResults() { |
如果我修改 useCallback 依赖项数组, 添加 query, 当 query 变化的时候, 任何使用到 getFetchUrl 的副作用函数都会重新执行:
1 | function SearchResults() { |
因为使用了 useCallback, 如果 query 参数始终保持不变的话, getFetchUrl 也就不会有变化, 那么副作用函数也就不会重新执行. 如果 query 变化了, getFetchUrl 也会同时发生变化, 然后重新请求数据. 这就好像是当我们修改 Excel 中的某个单元格之后, 其他单元格中的数据如果依赖这个单元格的数据, 就会根据新的数据重新计算对应的结果.
拥抱了数据流和同步的心智模型之后, 就自然会得到这样的结果. 同样的解决方式对于函数组件的 props 也一样有效:
1 | function Parent() { |
由于 fetchData 存在于 Parent 组件内部, 同时只有当 query 变化的时候, fetchData 才会变化, 因此我们的 Child 组件, 只有在需要的时机才会重新获取数据.
函数是数据流的一部分吗
很有意思的是, 这种模式在类式组件下就完全不适用了, 这也从另一方面体现出了副作用函数的心智模型和生命周期模式存在差异. 查看下面的对应类组件代码:
1 | class Parent extends Component { |
你或许会想: “我们都已经知道: useEffect 就像是 componentDidMount 和 componentDidUpdate 的结合体, 不需要时时刻刻重申这个观点!” 但是实际上, 这个观点是错的, useEffect 无法完全模拟 componentDidUpdate 的行为:
1 | class Child extends Component { |
当然了, fetchData 是一个类方法!(也可以说是类的属性 – 但是这并不能改变什么.) 即使 state 产生变化, 这个类方法也不会随之变化. 因此 this.props.fetchData 的值始终与 prevProps.fetchData 的值一致, 因此以上代码中的情况永远不会发生. 那么我们可以直接移除这个条件判断吗? 将代码修改为如下这样:
1 | componentDidUpdate(prevProps) { |
并不可以, 如果我们这样修改代码的话, 每一次重新渲染都会重新请求数据. (在组件树中添加一些动画能够更直观地观察到这个变化.) 那么如果将 fetchData 绑定到特定的 query 中, 会怎么样呢?
1 | render() { |
这样修改之后, 即使 query 没有变化, this.props.fetchData !== prevProps.fetchData 的值也始终是 true. 因此始终会重新请求数据.
对于这个问题, 唯一的解决方案是将 query 参数本身传递到 Child 组件中. Child 组件实际上并不会使用 query 参数, 但是在 query 变化的时候, Child 组件需要重新渲染以发起数据的重新请求:
1 | class Parent extends Component { |
很长一段时间, 我们使用的都是 React 类组件, 我很习惯将一些不必要的 props 传递到组件中, 习惯破坏父组件的封装. 直到一周前我才知道, 为什么我们必须要这样做.
在类组件的场景下, 函数的 props 本身并不是数据流的一部分. 组件的方法包裹了可变的 this, 因此我们不能够太过依赖方法的签名. 所以, 即使我们需要的只是一个函数, 也得同时传递一些其他数据, 这样 React 才能够方便地进行 “diff” 的操作. 同时, 我们无法知道从父组件中传递下来的 this.props.fetchData 本身是否依赖于某个 state 值, 这个 state 值是否变化过.
使用 useCallback 之后, 函数就能够参与到数据流中了. 如果函数接受的参数变化了, 那么函数本身也会变化, 否则就不会变化. 由于 useCallback 的功能足够完善, 属性的变化, 如 props.fetchData 也会传递下去.
类似地, useMemo 也提供了与 useCallback 类似的功能, 使得我们能够针对复杂的对象做出类似的处理:
1 | function ColorPicker() { |
我想要重点声明的一点是, 如果对每一个函数都用 useCallback 包裹, 代码会显得十分笨重. 有一种方式可以避免这种形式的代码, 当一个函数通过 props 传递, 并且在子组件内部被调用的时候, 这样的方式会很有用. 当你希望避免破坏子组件的缓存的时候, 这种方式也同样有用. But Hooks lend themselves better to avoiding passing callbacks down altogether.
在上面的例子中, 我更偏向于希望 fetchData 在我的副作用函数中(抽出一个自定义的 Hook)或者在顶层的 import 中声明. 我希望副作用函数尽可能保持简单, 内部声明太多回调函数会增加副作用函数的复杂性. (“What if some props.onComplete callback changes while the request was in flight?”) 你可以模拟类式组件的行为, 但是这并没有解决竞速场景的问题.
竞速场景
以一个典型的数据请求场景作为示例:
1 | class Article extends Component { |
可以看出来, 以上的代码其实是有 bug 的. 它并没有处理更新的情况. 现在我们加上更新的逻辑:
1 | class Article extends Component { |
后面一段代码示例做出了一些优化, 但是依然存在问题: 数据请求可能会出现顺序错乱的情况. 比如说, 当我用 {id: 10} 执行请求的时候, id 变成了 20, 在实际的请求过程中, 我们可能会先获取到 {id: 20} 的请求结果, 这样的现象就会导致 state 中存储的结果出现混乱.
这样的现象叫做: 竞速场景(Race Condition), 在存在 async / await 和数据流自上而下传递的代码中, 经常会发生这种情况(它假设了某些值会等待异步的结果, 但是代码执行到异步函数的中间时, props 或者 state 可能会发生变化.)
虽然在你传递 async 函数到副作用函数中时, 会抛出一些警告信息, 但是这仅仅是警告, 副作用函数并没有能力解决这个问题. (之后我们会改进这个警告, 以披露出更多有效信息, 告诉用户这样的使用方式会遇到的问题.)
如果你使用的异步方法支持被取消的话, 可以在清除函数中取消这个异步操作, 来解决以上的问题.
除了这种方式之外, 还有一个简单的方法: 添加一个标志来追踪请求是否被取消:
1 | function Article({ id }) { |
这篇文章详细阐释了你应该如何处理异常情况和加载的状态, 简单概括就是将这部分逻辑提取到一个自定义的 Hook 中. 如果想要学习更多有关于如何使用 Hook 请求数据的内容的话, 可以阅读这篇文章.
进一步深入
在类组件(生命周期)的心智模型下, 副作用函数的行为和渲染的结果有一定差异. UI 的渲染由 props 和 state 的变化驱动, 并且会确保渲染结果与两者的变化始终保持一致. 但是在副作用的心智模型下, 情况就不是这样了. 对两者的混淆, 也经常会引起一些 bug.
在 useEffect 的心智模型下, 默认情况下所有场景都是同步的. 副作用函数变成了 React 数据流的一部分. 如果开发者对于每一个 useEffect 都正确处理的话, 组件也能够更好地处理极端情况.
然而, 处理好 useEffect 的成本很大也很繁琐. 编写同步的代码, 处理极端情况, 比处理一次性的副作用(不严格与渲染的结果保持一致)难度大上很多.
如果我们在日常开发中经常用到 useEffect 的话, 情况就会变得很繁琐. 幸运的是, useEffect 是一个较为底层的 API. 因为目前尚处于 Hooks 出现的早期阶段, 因此大家会比较经常使用它, 特别是在某些教程中. 随着时间的发展, 社区会出现更多高阶的 Hooks API, 这样一来, useEffect 的使用场景就会变少.
据我了解, 目前已经有许多应用, 实现了一些自己的 Hooks, 比如 useFetch, 除了基本功能之外, 还封装了一些鉴权逻辑. 比如 useTheme, 则是利用 context 实现了切换主题的功能. 一旦我们封装了类似的自定义 Hooks, 用到 useEffect 的场景, 自然也就变少了. 尽管 useEffect 上手比较复杂, 但是它的能力也为基于它实现的 Hooks 带来了很多便利.
截止目前, useEffect 的大部分使用场景都是请求数据. 但是实际上同步的特性对数据请求的场景并没有什么大影响, 特别是大部分数据请求的场景下, 我们的依赖参数经常是空数组: [], 就更不会有太大的影响了. 那么同步的特性, 主要是用于影响什么的呢?
从长远角度看, 专门用以请求数据的 Suspense 特性 使得第三方库能够直接告诉 React 延迟渲染的流程, 直到某些异步的流程结束再开始渲染.
随着 Suspense 逐渐覆盖越来越多的数据请求场景, 我猜测 useEffect 会逐渐用于其他需要同步 props 和 state 至副作用函数中的场景. useEffect 的设计初衷, 也是处理这样的场景, 而并非数据请求. 到那时候, 类似这篇文章中的自定义 Hooks, 就会更多地被用于数据请求.
总结
我已经向大家介绍了我所了解的关于 useEffect 的知识点和使用场景. 现在可以再回看文章最开始的太长不看部分的内容. 是否对它们有更深入的理解了呢?